Problem
Modern IoT systems depend on many libraries, build tools, containers, firmware-adjacent utilities, and transitive dependencies. The security review surface is not limited to application code. It includes package metadata, lockfiles, build scripts, vulnerability advisories, SBOM entries, runtime evidence, and the ways those pieces connect to device identity, update paths, telemetry, and network transport.
AI-assisted development changes the review pressure. Codebases and dependency graphs can grow faster than a manual review process can comfortably track. That does not mean an AI model should make security decisions. It means the review workflow needs better ways to organize the evidence before a human reviewer decides what matters.
What I Built
I built local-ai-vet, a Rust CLI for local-first AI-assisted security triage.
The CLI takes structured security evidence, sends it to a local Ollama model,1 receives structured AI triage candidates, validates the referenced evidence IDs, and generates a Markdown review report for human approval.
The structured security evidence is designed to sit downstream of the evidence-based audit engine I built for IoT security and reliability. That engine generates deterministic, auditable artifacts from probes and rule evaluation, then those artifacts can be combined with supply-chain evidence such as:
- CycloneDX Software Bill of Materials data for Rust/Cargo projects, where the tool produces an aggregate SBOM of project dependencies.2
cargo auditvulnerability findings from the RustSec Advisory Database.3- Audit-engine findings, baseline diffs, scanner findings, and system context from the wider review workflow.
That combination matters because dependency review is stronger when an advisory or SBOM entry is connected to system context. A vulnerable dependency in an unused developer tool is not the same as a vulnerable dependency on a device identity, certificate validation, MQTT, TLS, serialization, or update path.
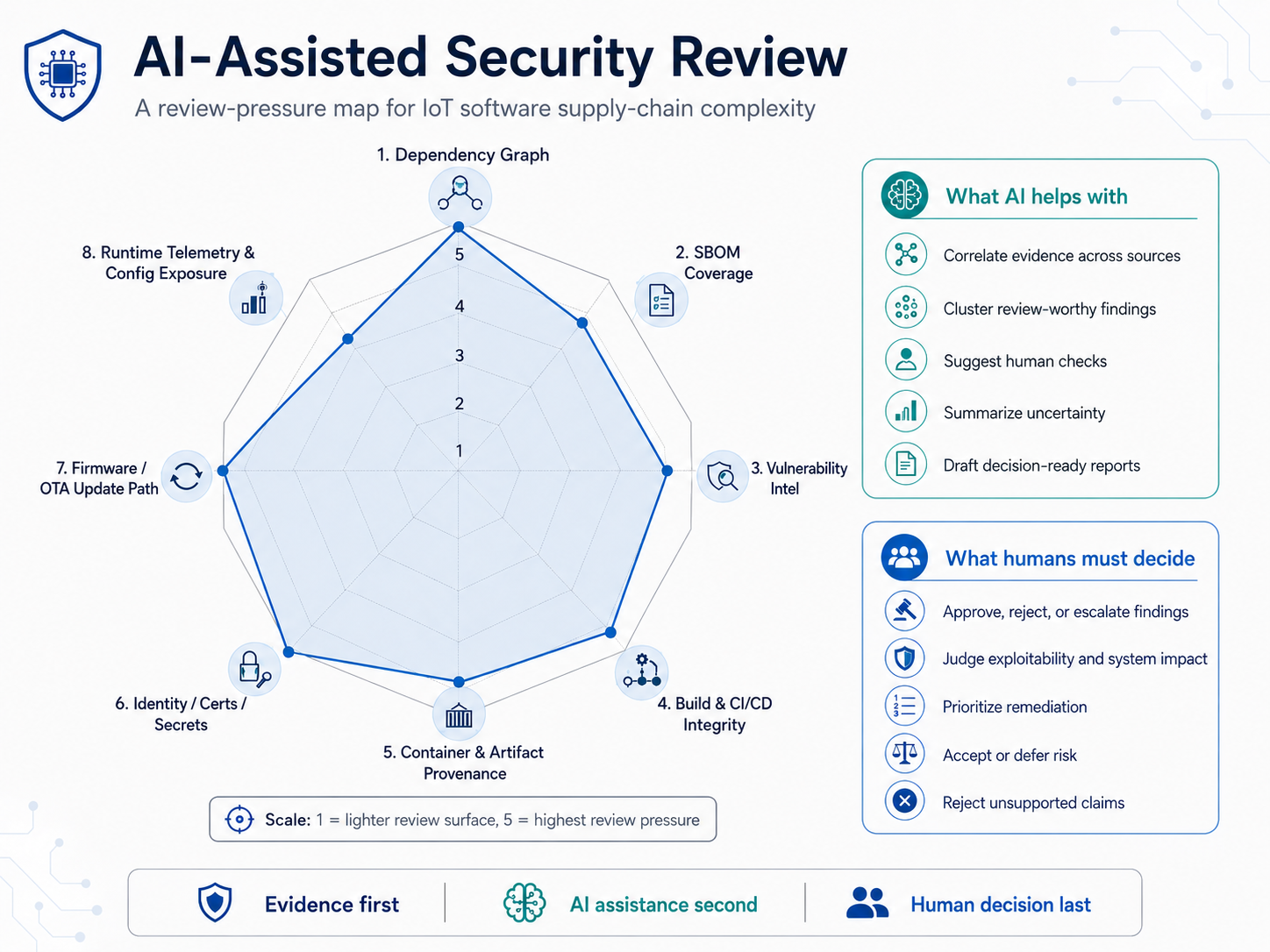
The review-pressure map shows the kind of context the workflow is meant to keep visible. Dependency graph shape, SBOM coverage, vulnerability intelligence, build provenance, container artifacts, certificates, update paths, and runtime telemetry all affect how seriously a finding should be reviewed. The point is not to assign a universal risk score. The point is to give the reviewer a structured way to see where AI assistance can correlate evidence and where a human must still judge exploitability, remediation priority, and accepted risk.
The related design context is documented in Designing an Evidence-Based Audit Engine for IoT Security & Reliability.
Why It Matters
The AI does not make final security decisions.
It helps organize evidence, summarize review-worthy candidates, explain IoT relevance, suggest human checks, and prepare a structured report. The human reviewer remains responsible for approval, rejection, escalation, accepted risk, or asking for more evidence.
That boundary is important. A model can be useful at turning a large evidence pack into a review queue, but it should not be allowed to invent CVEs, package names, versions, exploitability claims, remediation facts, or unsupported references. The workflow is intentionally shaped around evidence first, AI assistance second, and human decision-making last.
Technical Slice
- Rust CLI
- Local Ollama model
- JSON evidence input
- Structured triage output
- Evidence ID validation
- Markdown report generation
- Human-in-the-loop review flow
The CLI exposes three core commands:
triagereads a JSON evidence pack, calls the local model, and writes structured AI triage output.validatechecks that each finding candidate references evidence IDs that actually exist in the input pack.reportrenders the validated triage output into a Markdown review report.
The report format is deliberately practical. Each candidate includes affected components, evidence references, why the issue is review-worthy, IoT relevance, suggested human checks, uncertainty, and explicit human decision checkboxes.
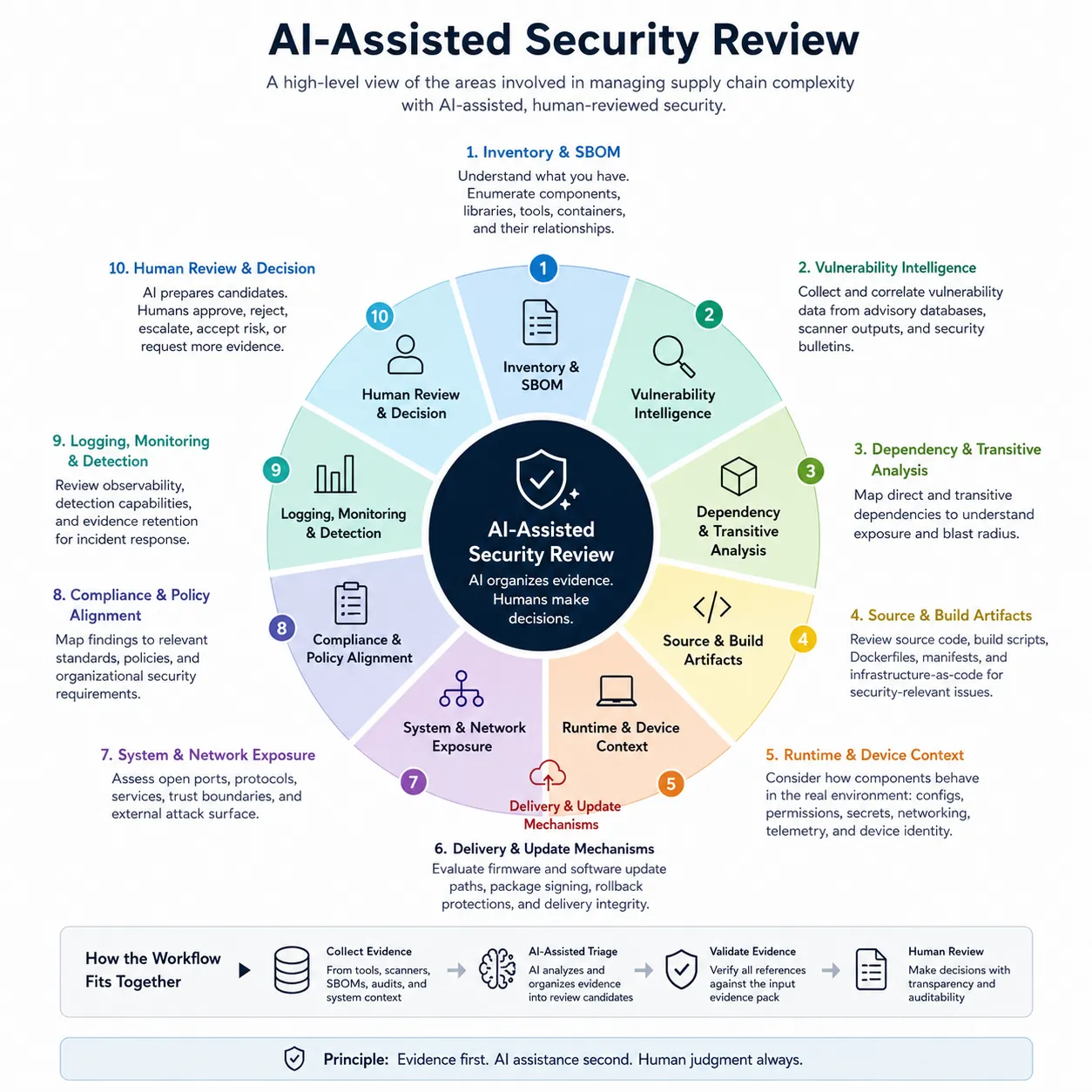
The workflow overview describes the boundary between evidence collection, model-assisted triage, validation, and human review. Inventory and SBOM data establish what exists. Vulnerability intelligence, dependency analysis, build artifacts, runtime context, update mechanisms, network exposure, policy requirements, and monitoring evidence add operational meaning. The model organizes that evidence into candidates, but the review record only becomes useful after references are validated and a human approves, rejects, escalates, or requests more evidence.
Security Principle
AI suggestions must be grounded in real evidence.
Unsupported evidence references are rejected before entering the review report. Candidates with no evidence references are also rejected. The prompt tells the model to use only supplied evidence and to treat package source, metadata, README files, comments, and build scripts as untrusted input.
This is the core principle behind the prototype: AI may assist the reviewer, but it does not get to smuggle unsupported claims into the decision record.
Outcome
The result is a prototype workflow for scaling security review across IoT and software supply-chain evidence without relying on cloud AI or unchecked model output.
It demonstrates a useful pattern for software engineering work around AI-assisted security:
- keep sensitive review context local where possible
- represent evidence as structured data
- ask the model for candidates, not final decisions
- validate evidence references before report generation
- preserve uncertainty instead of hiding it
- make the human review step explicit
The value is not that AI replaces security judgment. The value is that a reviewer can move through dependency, SBOM, vulnerability, and audit-engine evidence with a better prepared queue and a clearer decision trail.
References
Footnotes
-
Ollama is used here as the local model runtime for AI-assisted triage. ↩
-
CycloneDX, cyclonedx-rust-cargo, creates CycloneDX SBOMs for Rust/Cargo projects. ↩
-
RustSec,
cargo-audit, audits Rust dependencies for vulnerabilities reported to the RustSec Advisory Database. ↩
