Context
This was built for edge-to-cloud IoT systems where TLS, MQTT, gateway behavior, and unstable networks create drift over time.
The objective was to move audits from one-time assessments to a repeatable control loop.
For the deep technical design context, see the blog post section on the problem and system boundaries.
Intervention
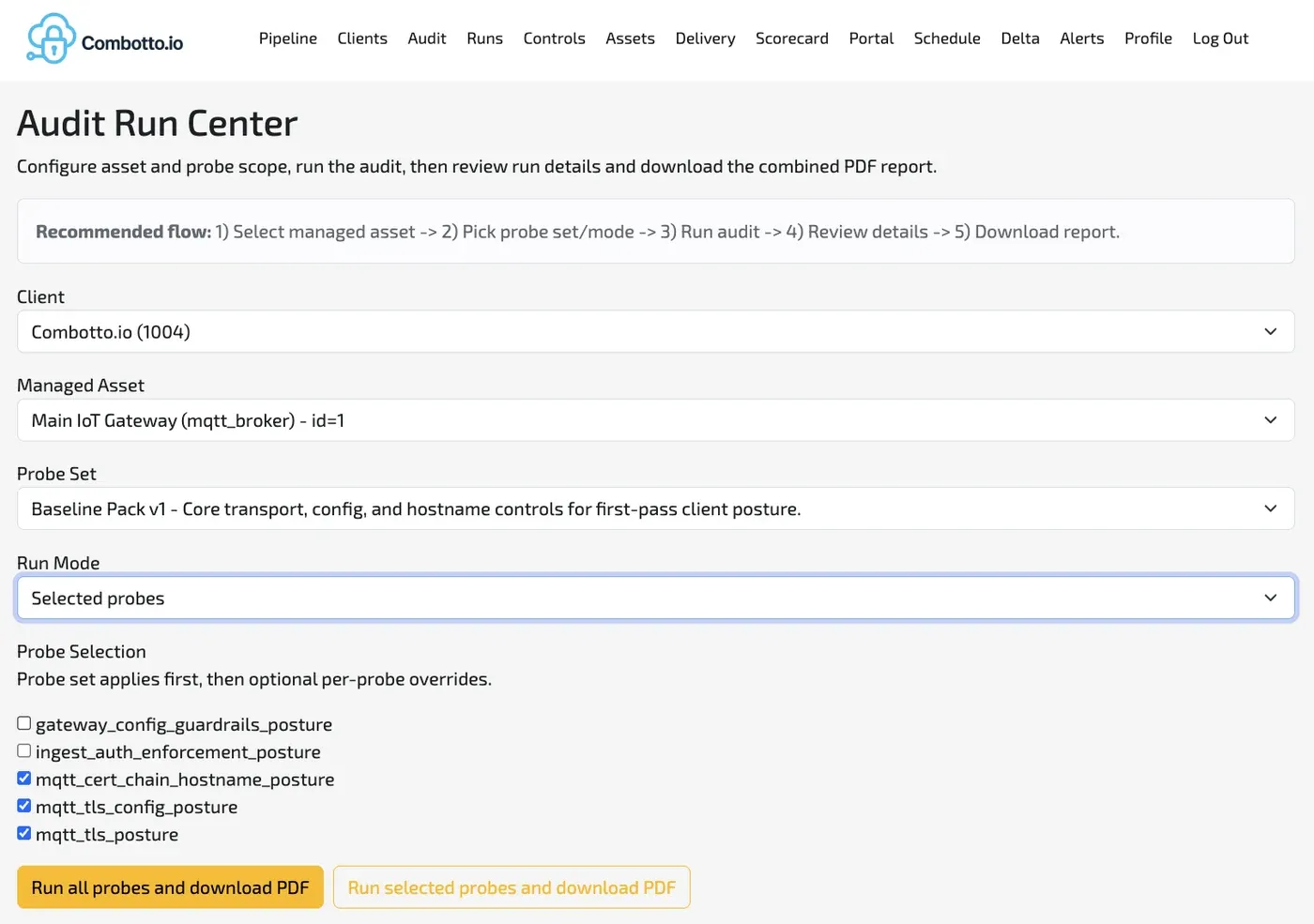
I designed and implemented an evidence-first audit engine with a deterministic flow:
- Collect probe evidence from target assets.
- Normalize and evaluate evidence using versioned rules.
- Produce issue drafts and report artifacts.
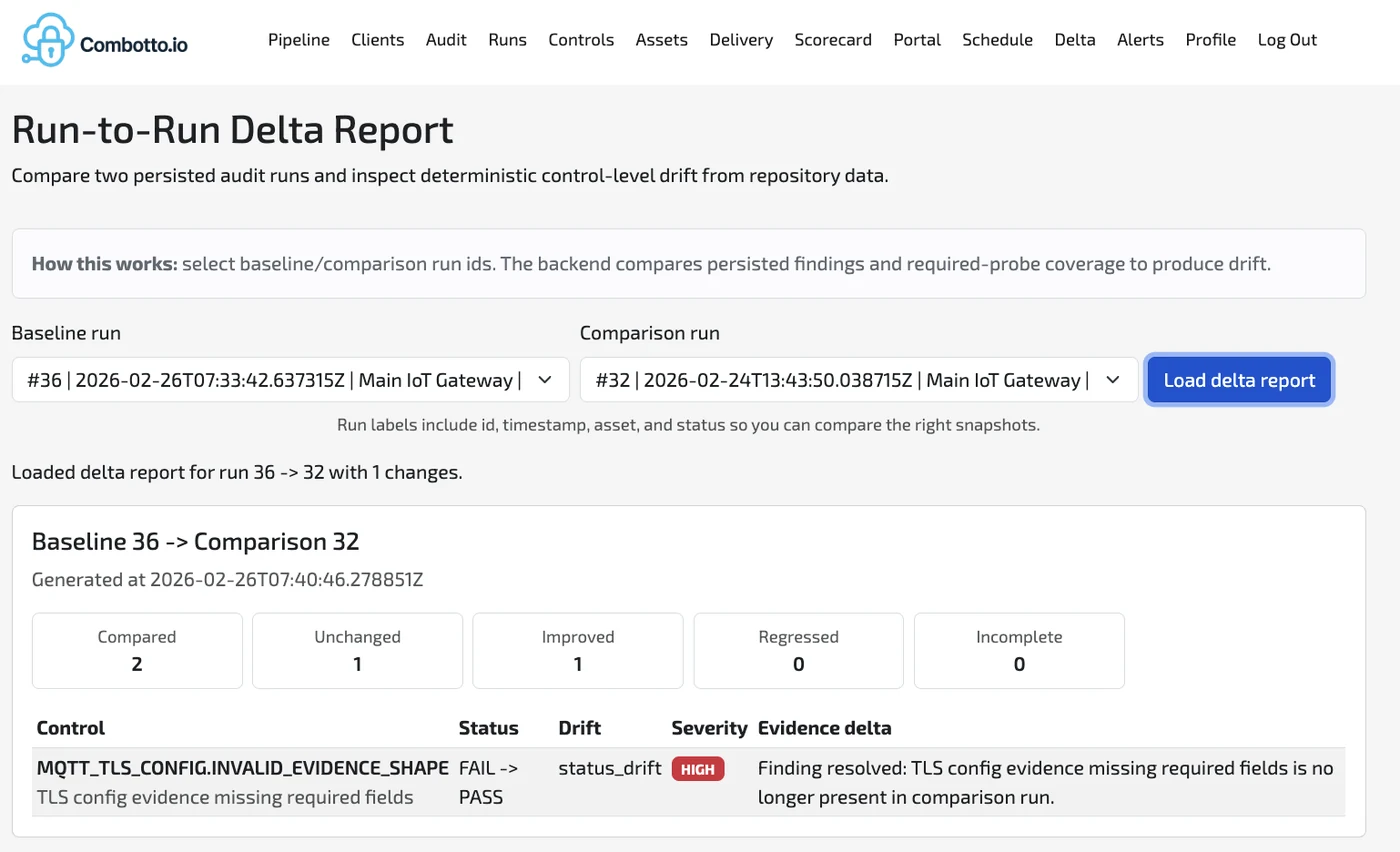
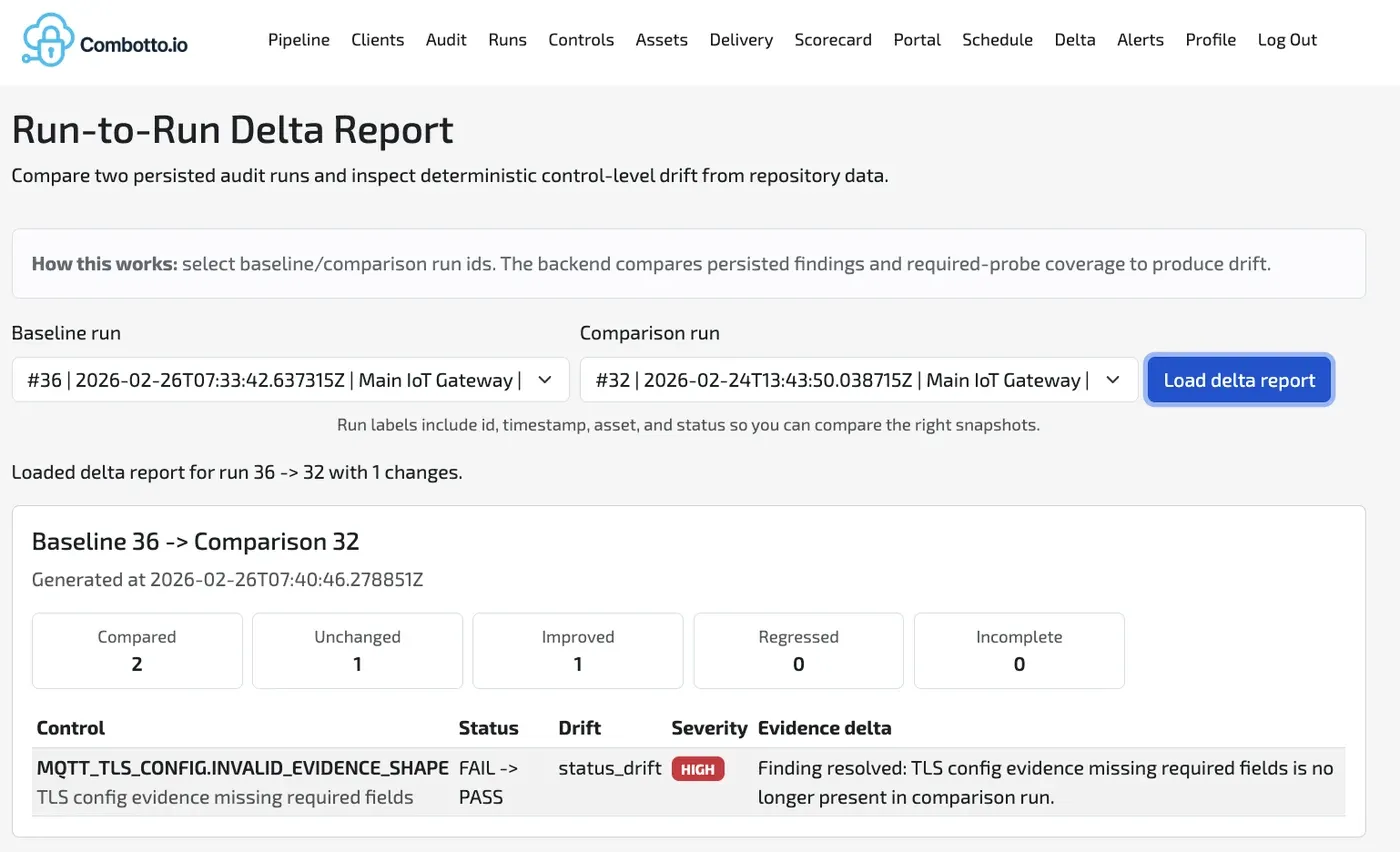
- Compare runs to surface deltas and regressions.
- Feed outcomes into a re-runnable engineering backlog.
Technical implementation details are documented in:
Evidence
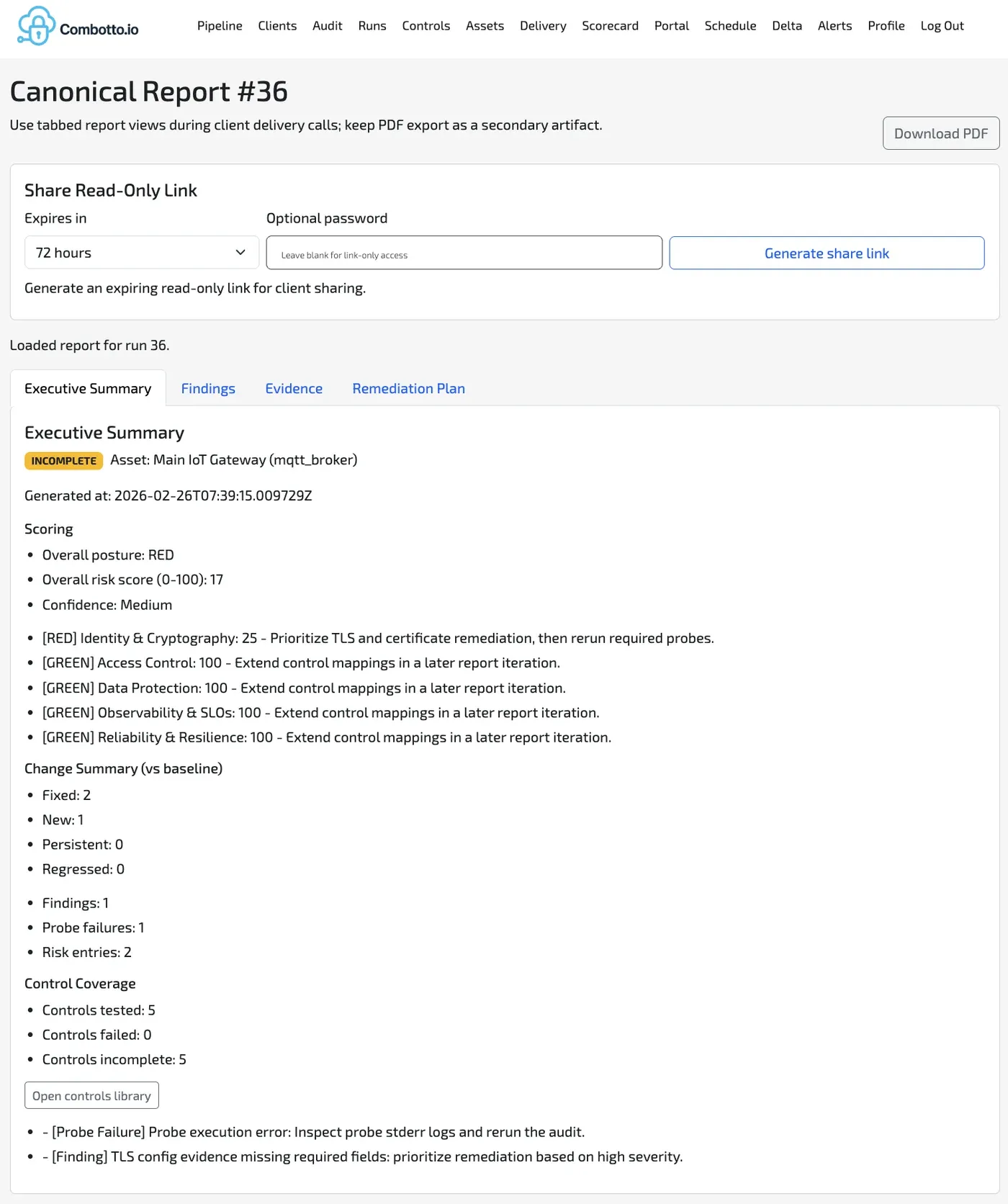
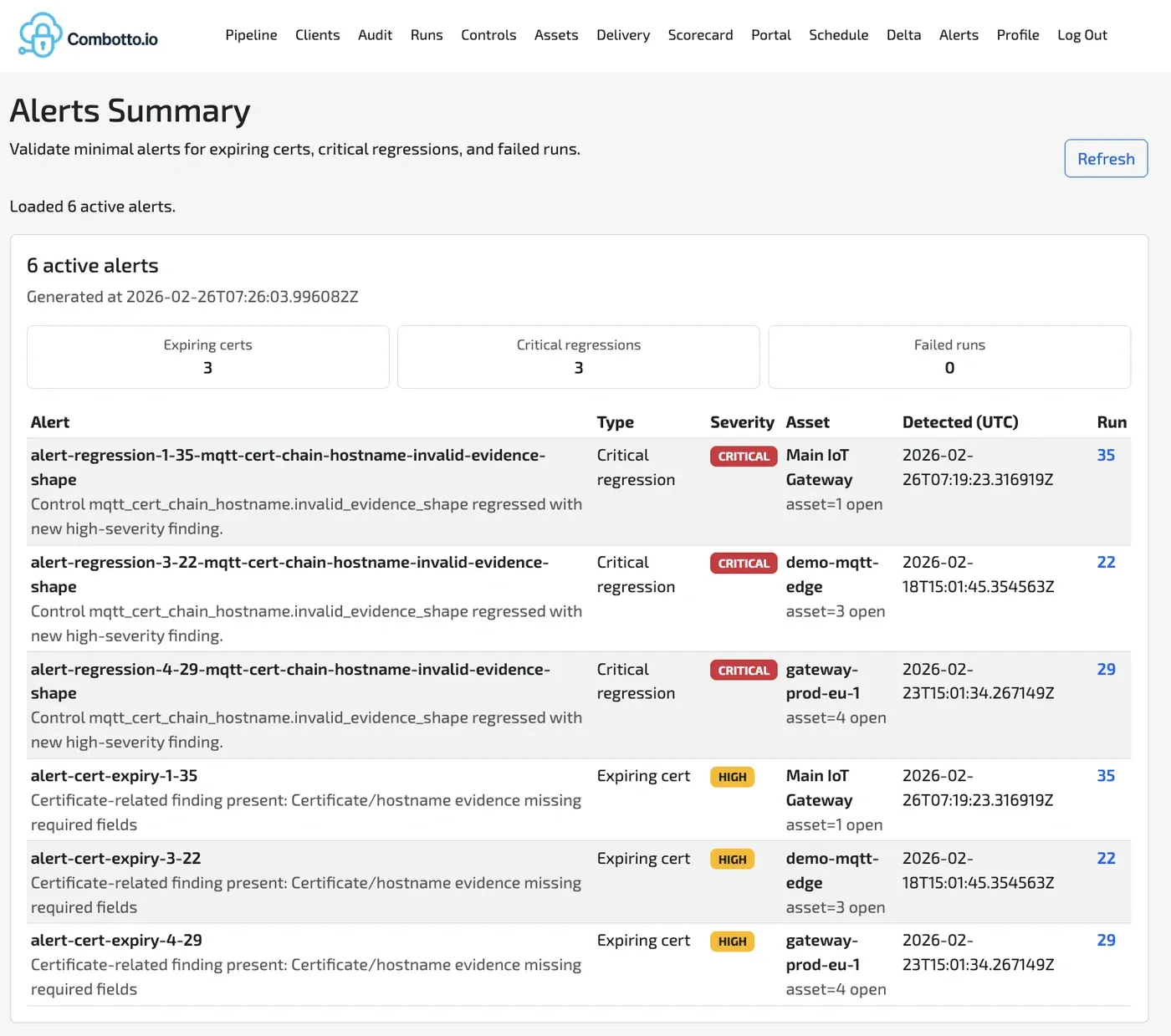
The platform generates auditable artifacts, not just recommendations:
- Structured raw evidence from each probe execution (JSON contract per check).
- Rule-evaluated findings with severity and issue keys.
- Run records that allow run-to-run comparisons and drift detection.
- Backlog-ready issue outputs that can be scheduled and re-verified.
This enables a “show, do not tell” audit style where each finding has traceable evidence and a deterministic rerun path.
Outcome
Engineering outcomes from this implementation:
- Audits moved from manual snapshots to repeatable, evidence-backed runs.
- Findings became measurable across cycles through deltas and regression checks.
- Reliability, security, and observability could be assessed in one operating model.
- Follow-up work became operational through generated, prioritized backlog items.
Next Step
This engine is a reusable proof asset for how I approach evidence modeling, deterministic audit execution, and backlog-oriented hardening in IoT systems:
- Review the deep dive for the architecture and implementation details behind the run model.
- Browse the wider portfolio for related gateway, telemetry, and reliability work.
Read the full deep dive or view more portfolio work.
Tech Notes
Small probes and deterministic orchestration make this practical for real projects where teams need repeatability, traceability, and an upgrade path rather than one-off reports.
Stack: Rust probes + Scala/ZIO service + Postgres + report/backlog generation + CI-friendly execution.
